
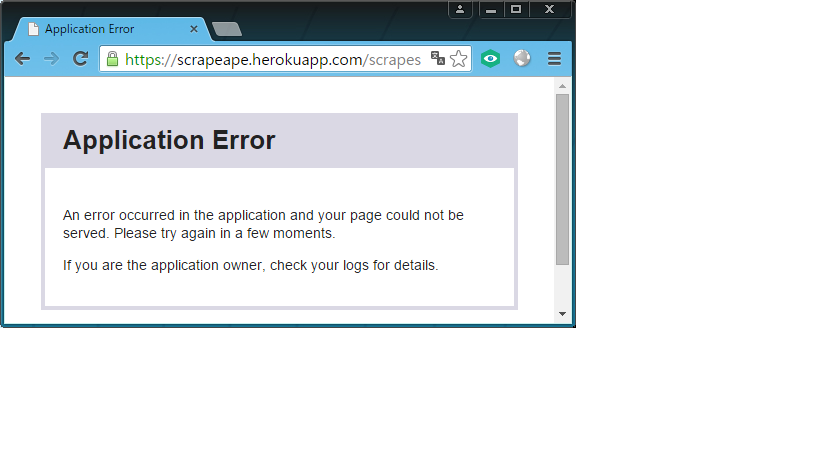
最近このブログで何かと話題にしている伝十郎氏のWebサービスですが、『ScrapeApe』というWebサービスを新たに開発したようなので、今回は紹介を依頼されているわけではありませんが、素晴らしいWebサービスだったので勝手に紹介してみようと思います。
ScrapeApeとは
URLとスクレイピングしたい部分のXPathを登録すると、毎日自動でそのページを取得してスクレイピングした結果を一覧で見ることができるサービスです。

ScrapeApeを検証
ユーザー登録不要で誰でも利用できるようになっているので、いろいろ試してみました。
文字化けするページがある
いくつか適当なサイトをスクレイピングしてみると、文字化けするページがありました。
ブラウザで見るとちゃんと日本語が表示されていて、エンコーディングはUTF-8。
metaタグのcharsetも正しく設定されていて、特におかしなとろこはないように見えるのですが、ScrapeApeではなぜか化けてしまいます。
文字化けするURLとそうでないURLのレスポンスを見比べてみると、謎は氷解しました。
どうやら、レスポンスのContent-Typeヘッダにcharsetパラメータが指定されていないと文字セットが正しく解釈できずに文字化けしてしまうようです。
charsetの指定がない場合、文字の化け方から、ISO-8859-1で解釈しているみたいです。
文字化けが起こると、無知なユーザは反射的に「プログラムのバグだ!」と決め付けがちですが、RFC 2616 §3.4.1にも書かれているように、HTTPのクライアントに文字セットを正しく解釈してほしければ、サーバー側がちゃんとContent-Typeヘッダにcharsetパラメータを指定すべきなので、安易にバグといってはいけません。
ヘッダにcharset指定がないページはISO-8859-1として解釈するというのがScrapeApeの仕様なのでしょうから、ユーザーはそのような行儀の悪いサイトを避ければよいのです。
robots.txtの扱いは?
Webを自動巡回する系のサービスなので、robots.txtの扱いが気になります。
自分のサイトに「Disallow: /」なrobots.txtを置いてScrapeApeからスクレイピングを
試してみましたが、普通に取得できました。robots.txtは見ていないようです。
例えば、ウェブ魚拓は、“著作権法で「robots.txtで情報の収集を拒否するページの情報収集の禁止」が定められている”として、robots.txtの記述に従っているそうですが、軽く調べてみると、「robots.txtで拒否しているページの情報収集は違法」ということではなく、情報検索等のサービスに必要な情報収集や検索結果の表示等の行為を(著作権法に対して)合法的に行うための要件の一つに「robots.txtで拒否しているページの情報収集の禁止」があるということらしいです。
というわけで、robots.txtに従っていないからといって違法ということにはなりません。
もちろん、著作権のあるページを無許諾でスクレイピングして公開すれば著作権侵害となる可能性はあるでしょう。
しかし、悪意あるユーザーに対しては、URL登録時のIPアドレス等を記録するなどしっかり対策はしているでしょうから、
我々善良なユーザーとしては、スクレイピングの対象を著作権の発生しないデータ等に限って利用している限り、特に心配は不要と思われます。
Rails?のエラーページがよく出る
例えば、存在しないページ(404)をスクレイピングしようとすると、
「We’re sorry, but something went wrong.」というRails?のエラーページが表示されます。
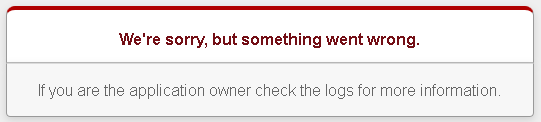
英語で何のエラーかよくわからないので不親切な気がしますが、気にしてはいけません。
我々はもっと不親切なエラー画面をよく目にしているはずです。
むしろ、Rails製のWebアプリではよく見る画面なので覚えておき、これを見たら
「あーなんかエラーなんだな」と分かるようになりましょう。
稀にしか発生しない例外をハンドリングしていないだけなのです。
こういった例外的な処理を省くことで本質的なコーディングに注力しているのでしょう。
最後に
いままでありそうでなかったScrapeApeというWebサービスですが、いろいろ触ってみた結果とてもよくできていることがわかりました。
そもそも、スクレイピングという行為は一見簡単そうに見えて実は結構大変です。
HTMLが歪だったり、謎の文字セットが指定されていたり、そもそもHTMLですらなかったり、
ユーザーが登録したURLはどんなレスポンスを返してくるかわかりません。
使用しているライブラリの脆弱性を突こうとする悪意あるデータが降ってくるかもしれません。
登録URL数や巡回頻度が小さいうちは問題なくても、これらが大きくなってくると
自動巡回時のパフォーマンスについても考慮しなくてはならなくなります。
データ送受信時のタイムアウトだとか、HTTPアクセスの並列化だとか、DNS解決が遅かったりキャッシュを持ちたくなったり、いろいろ問題は出てくるでしょう。
サービスを公開すること自体のリスクというものも気になってくるかもれません。
悪意あるユーザーに法的にアウトな情報を登録されたらどうしようとか。
ログの保存件数やデータのバックアップは問題ないかとか。
挙げていけば気になることは無数にあります。
しかし、そんなことをいちいち気にしていてはWebサービスなんて作れません。
伝十郎氏も言っているように、作りたいものが作れる知識だけ得られればよく、上に書いたような細かい話はどうでもよいことではないでしょうか。
世知辛い世の中で、趣味で作ったWebサービスでも、重箱の隅をつつくような批判を受けたり、やたらとDISってくる糞みたいなブログもありますが、
そんな声は無視して、伝十郎氏にはぜひ今後も素晴らしいWebサービスを作り続けて欲しいと思います。

コメント
やたらとDISってくる糞ブログなんてあるのかよ最低だな
> ヘッダにcharset指定がないページはISO-8859-1として解釈するというのがScrapeApeの仕様なのでしょうから、ユーザーはそのような行儀の悪いサイトを避ければよいのです。
伝十郎さんが作ったオンラインメモ(http://onlinememo.net/)はcharset指定ないんだが???
伝十郎さんのことDISってんの???
HTTP/1.1 200 OK
Date: Wed, 02 Dec 2015 11:01:01 GMT
Server: Apache
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Keep-Alive: timeout=2, max=20
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: text/html
ほらxx2zzがDISるからonlinememoのサーバー引っ越ししてしまってScrapeApeのロゴが出なくなっちゃったじゃん。
HTTP/1.1 302 Found
Connection: keep-alive
X-Frame-Options: SAMEORIGIN
X-XSS-Protection: 1; mode=block
x-content-type-options: nosniff
Location: http://onlinememo.net/users/login
Content-Type: text/html; charset=utf-8
Cache-Control: no-cache
Server: WEBrick/1.3.1 (Ruby/2.0.0/2015-12-16)
Date: Thu, 14 Jan 2016 04:08:11 GMT
Content-Length: 99
Great, thanks for sharing this article.