

いかに(2つの意味で)適当にデータを収集するかというお話。
経緯
明日も朝から実験があるのでこんなクソブログに記事書いてる場合じゃないんだが、自分的にあまりにも上手く行ったので残しておく。
以前どっかの記事で心理学やってますみたいなことちらっと書いた気がするんだけど、心理学は心理学でもあまり心「理学」っぽくない領域が専門だったりする。どっちかと言えば工学的要素が強い応用行動分析が専門で、この分野はSkinnerもBeyond freedom and dignityでBehavioral Engeneeringをトゥギャザーしようぜみたいな感じで言ってた気がする(うろ覚え)し、ええ感じに上手いことやりましょうや的発想が求められる。と勝手に思ってる。
心理学全般で言えば、輸入の学問なので用語が統一されていないところがある。(例えば「inhibition」が「抑制」と「制止」みたく異なる訳を受けたり)
一方で行動分析学に関して言えば、国内で用語の統一をしようという試みもあった(島宗 他, 2003, 行動分析学研究, 17, 174-208)がどれぐらい浸透しているかはわからない。(12年経ったけど書籍で用語の使われ方がどう変化したのかという研究はあっていいかも っていうか既にありそうだがそこまでこのトピックに興味あるわけでなし調べてない)
というのが現状としてあったので、データとしてまとまった形で用語集が欲しかった。
前から存在は知ってたし度々参照してたけど、おそらく島宗先生がネットに公開したと思しき用語集がある。おそらくと書いたのは、ドメインが島宗先生の前の所属先でサイトのデザインもなんとなくそんな感じだからそう思ってるだけ。署名がないから実際にそうなのかはわからないが、十中八九まあそうだろう。
見ていただいたらわかるように、このままでも非常に見やすい。ゴマを擂ってるわけじゃないけど、よくまとまっているし、結構な労力を割かれたのだろうなという印象を持つ。なんとかして扱いやすいデータ、つまりCSV形式にできないだろうかと考えるのは不思議ではないはず。こういう経緯で今回CSV化するに至った。
どう調理してやろうか編
相変わらず前フリの長いのが僕の短所だな。まあいいや。
大抵のプログラマはこういう状況でHTMLソースを見て記述パターンを解析するコードを書くと思うけど、今回それは断念した。
なぜか。ソースを見ていただいたらわかるように、HTML的な意味で構造化があまり正確にされていなくてパターンを抽出するのが面倒だったからだ。おそらくこのような文書なら<dl>を用いて色やサイズ等に関してはCSSに投げた方が良い。(ページ製作者の名誉のためにフォローしておくと2001年当時はこのような「HTMLはデータ」という発想はあまりなく、そもそもこのページはAdobeのソフトが出力しているために糾弾されるべきは当時のAdobe社である)
そんなことを言ってても仕方ない。ページをざっと眺めると次のような特徴があることに気づくだろう。
- だいたい3行ぐらいで収まってるっぽい
- 最初の行は見出し
- 最後の行は属性的なのに割り当てられていて、しかもその記述は[]に入れられており統一されている。
つまり、ブラウザ上で表示されているテキストをコピーしても構造的な情報は損なわれなさそうである。むしろ、HTMLを見るより綺麗に整頓されていることに気づく(このあたりにページ製作者の労力が伺える)。これを利用しない手はない。今後このページが更新されることもなさそうなので、一回限りの作業で良い。今回は家で作業するので神言語Perlの出番である。
お前もCSVにしてやろうか~~~
とりあえず表示されているテキストをコピーしてテキストエディタに貼り付け、最初の凡例部分までを手動で削除する。一回限りの場合は手動のほうが手っ取り早いこともある。
この時点でこんな感じ。
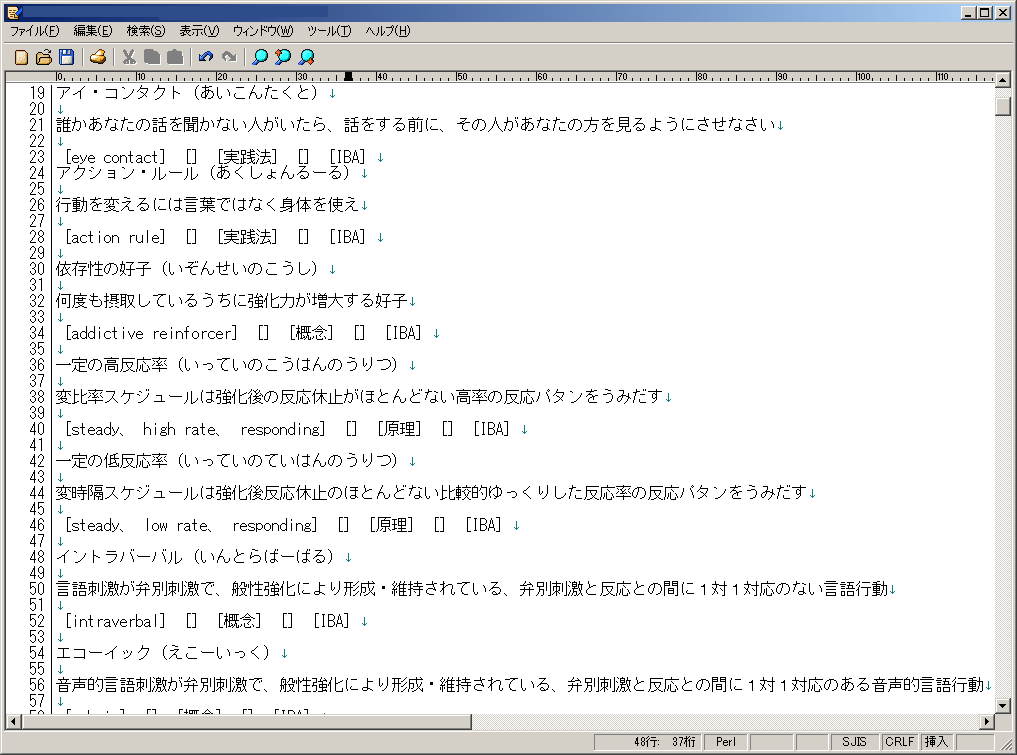
良い感じである。
画像を見てもらったらわかるように、行のインデックスが19から始まっている。これはこの上にPerlのコードをぶち込んでいるからだ。データを含んだ全体のPerlファイルは著作権的にアレなので公開しないが、このPerlコード部分だけ公開しようと思う。
[perl]
use strict;
my @data = do{
local $/ = "]\n";
<DATA>;
};
my @dic;
my $h;
y/,/ / xor s/\r//g xor y/\n//s xor /^([^\n]+)\n(.+)\n([^\n]+)$/m xor $h = $2 xor $h =~ y/\n//d xor push @dic, join’,’,@{[$1,$h,$3]} for@data;
$, = $/;
print @dic;
<>
__DATA__
アイ・コンタクト(あいこんたくと)
誰かあなたの話を聞かない人がいたら、話をする前に、その人があなたの方を見るようにさせなさい
…
[/perl]
こんな感じ。面倒なのでいちいち解説はしないけど、使い方的にはコマンドラインから開いてhoge.pl > fuga.csvみたいにするとCSVファイルが生成されて万々歳となる。
抽出されたデータはあってるのか
さてCSVで保存され万々歳となったが、本当に全部が正しく抽出されているのか。
エクセルでCSVを開いてCtrl+↓で空いているセルがないか確認した(Ctrl+↓でブランクのセルの直前まで移動してくれる)ところ、文中にカンマがあるとかでセルがズレてるとかそういう不備はなかった。
個数はあっているのか。再びブラウザの表示を見ると、項目は水平線<hr>で区切られていることがわかる。今度はソースから攻めよう。
まずHTMLソースをコピーして貼り付け、余分な箇所(凡例まで)を削除する。その後、その編集されたHTMLソースを再びコピーし、今度はエクセルに貼り付ける。エクセルでは改行を含むテキストを貼りつけると、行が変わって入力される。この状態でエクセルの検索機能で「<hr」を調べるだけだ。195個。抽出されたデータ数と一致した。めでたしめでたし。
まとめ
パッと見で規則性を抽出しようとするヒューリスティックスはなんだかんだで上手くいく。上手くいくからヒューリスティックスなんだが。ちなみに僕はこういうのを「目grep」と呼んでいる。使っていいよ。
そのうち、今回得たデータを使った何かを出すと思う。
今回はここまで。
おしまい。

コメント