
2017年08月21日追記
UIや機能を改善したver2が公開されています。以下のページを参照してください。

最近とあるサイトからデータを拝借したかったけど30ページ以上に分かれており、構造としては同じなものの、タグにclassがうじゃうじゃついていて面倒という事があった。
ちょうどUWSCで似たような処理を書いた後だったので、そのコードを流用してURL入力で不要な文字列をカットしてクリップボードにぶち込むようにしたのだけど、せっかくなのでブログのネタとして公開することにした。
構造が同じ複数のページから情報をまとめて引っこ抜きたい時などに是非活用して欲しい。
なお、名前に関して知る人ぞ知る神サービスに影響を受けたことは間違いない。
ScrapeHumanの機能
対象URLのhtmlソースを取得し、整形してクリップボードもしくは任意の拡張子のファイルとして吐き出す。
設定ファイル(ScrapeHuman.ini)に自由に設定を書き足して使用できる。
機能的なものとしては以下。
- 同一設定でURLの複数指定が可能
- 開始位置の指定(指定した文字列のn個目からも可能)
- 終了位置の指定
- NGワードの設定
- 出力形式をクリップボードに保存もしくは任意の拡張子のファイルで吐き出す
- HTMLタグカット機能(空行、スペース・タブ行、インデントも同時に削除)
ScrapeHumanの使い方
ScrapeHumanのダウンロード、インストール、使い方を解説する。
動作環境はWindows XP/Vista/7/8.x/10 なら大丈夫だろう。
ダウンロードとインストール
ダウンロードは以下のリンクから。修正・改変・再配布などは禁止。
インストールはダウンロードしたzipファイルを適当なフォルダに解凍するだけ。
アップデートの方は中身を上書きでOK。
“ScrapeHuman1.5.1” をダウンロード ScrapeHuman1.5.1.zip – 3797 回のダウンロード – 1.25 MBもしくはVectorからもダウンロード可能。
ScrapeHumanの詳細情報 : Vector ソフトを探す!
初回起動
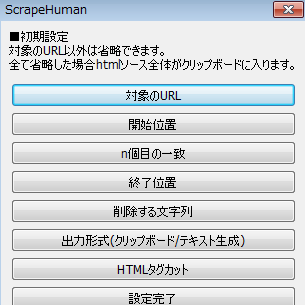
ScrapeHuman.exeの初回起動(設定ファイルが存在しない場合)では設定画面が出る。
スクレイピング先のURLが必須で、後は目的に応じて変更したらよい。
設定完了を押すと設定がScrapeHuman.iniに保存され、そのまま初回のスクレイピングを終える。
設定の追加・変更
ScrapeHuman.iniを編集して、設定を変更したり追加したりできる。
追加する設定には数字をつけて全体設定で指定する。
[全体設定]
■終了時ダイアログ=1
1→終了時ダイアログを出さない 0→出す
■使用設定=1
どの設定を使うか選択する。設定は以下のように追加する。
[設定2] ※この設定を使いたい場合、使用設定で2を指定する
■URL=http://example.com/
http://かhttps://から始まる必要がある。「,」区切りで複数指定が可能。
出力形式設定がないと最後のURLの実行結果のみクリップボードに入る。
■開始位置=<body>
省略した場合は先頭から。
■x個目の一致=2
開始位置と一致した文字列のx番目を起点に設定する。
省略もしくは存在する数より大きい数値を指定した場合は最初に一致したものを取得。
■終了位置=</body>
省略した場合は最後まで取得される。
■NGワード=上に戻る,</li>
「,」区切りで指定する。今のところ「,」自体は扱えない。
■出力形式=txt
空にすると結果がクリップボードに入る。テキスト以外でもなんでも指定できる。
URL毎にフォルダが作成され、その中に保存される。
ファイルはUTF-8で出力される。
■HTMLタグカット=1
1→HTMLタグをカットする 省略→カットしない。
HTMLタグカットを選択した場合、空行、スペース・タブ行、インデントも同時に削除される。
完璧に動くかは判らないので、動作がおかしいと思ったらNGワードを活用する事。
アップデート・バグ報告
アップデート情報
Ver1.5.1(2016/04/12)
フォルダ名(ファイル名)に使用できない文字がURLに含まれていた場合のファイル出力エラーを修正。
Ver1.5(2016/01/27)
せっかくなのでサイトで公開。
バグ報告
バグ報告や機能の追加希望があれば、ktm@sに直接連絡を取るかこちらの記事にコメントを。
バグはできるだけ早くつぶすつもりだけど、機能に関しては実装するか判らないよ。

コメント
気になるアノ子の郵便受けをスクレイピングする機能ください!!!1おねがいします!!!111
ピザのチラシが返ってきます。
とても便利に使わせていただいています。
1点不具合と思われる動作がありまして
‘?’などのファイル名に使用できない文字が含まれるURLを対象にすると
テキスト出力の場合にエラーとなるようです。
現状はクリップボード出力を使うようにしていますが
こちらの改修が可能であればぜひお願いできればと思います。
こんにちは。
情報ありがとうございます。
確かに全く考慮しておりませんでした。
ただ今出先ですので帰宅次第修正して公開します。
修正しました。
Ver1.5.1をダウンロードして中身を上書きしてください。
報告ありがとうございました。
まさしくやりたかったことが実現できそうなツールで非常に胸を膨らませているのですが、「一致するもの全て」を抽出することはできないのでしょうが。これができると本当に便利なのでとても期待しています。
>>>>■x個目の一致=2
開始位置と一致した文字列のx番目を起点に設定する。
省略もしくは存在する数より大きい数値を指定した場合は最初に一致したものを取得。
今のところそういう使い方ができる機能はないですね。
さっきソースを読んだのですが、元々公開ありきで作ったツールではないので中々に汚いです。
実装はできても今すぐとはなりません。
一応頭には入れておきますが、あまり期待しないでください。
ありがたく使わせていただいています。
可能であれば以下2点の実装していただけると大変助かります。
・HTML構造エラーでデータ取得できない場合に、ストップするのではなく、スキップする
・処理完了後にログを吐いて、HTML構造エラーで取れなかったものがどれかが分かる
コメントありがとうございます。
ご要望に関して、ScrapeHumanは自分の作業にちょろっと書いたツールで随分不完全です。
(エラー処理なんてまさにそれで、作業時に取得できないわけがなかったのでそのままです)
思ったより要望が出たため今後はちゃんとしたツールとしてC#移植を予定していますから、その際にこれまでのコメントの要望をまとめて実装したいと考えております!
やる気とかいうラスボスとの戦いです。気長にお待ちください。